LLM-Agnostic vs. Locked-In: Why Your Enterprise AI Platform Choice Will Define the Next 5 Years
In early 2023, GPT-4 was the clear frontier model. Every serious enterprise AI initiative was built around it. By late 2024, Claude 3 and Gemini Ultra had closed the gap significantly. By 2025, DeepSeek's open-weight models were outperforming proprietary alternatives on several benchmarks at a fraction of the cost. In 2026, Kimi K2, Grok 3, and a dozen other models are credible options for specific enterprise tasks.
The model landscape is moving faster than any enterprise procurement cycle has ever moved.
And yet, many organizations are making a multi-year platform commitment that ties their entire AI infrastructure to a single model provider. They are signing contracts, building workflows, and training teams - all on the assumption that the model they are locked into today will still be the right choice in 2028.
That assumption is almost certainly wrong. And the cost of getting it wrong is not a painful migration. It is years of competitive disadvantage while rivals who made more flexible choices continue to compound on better models, lower costs, and faster capabilities.
This is the most important strategic decision in enterprise AI right now. Most organizations are not treating it that way.
What Happened to Enterprises That Bet on a Single Cloud in 2010
Before getting into models specifically, it is worth remembering what happened to organizations that built their entire infrastructure on a single cloud provider in the early 2010s.
Some of those bets paid off. AWS customers who went all-in early got pricing advantages and deep feature integration. But many organizations found themselves unable to negotiate on price, dependent on a single vendor's roadmap for critical capabilities, and facing expensive multi-year migrations when their needs evolved or better alternatives emerged.
The enterprise technology industry spent the better part of a decade learning the lesson that infrastructure lock-in is a strategic liability. Multi-cloud became standard practice not because running workloads across AWS and Azure is technically elegant, but because optionality has real business value.
The same dynamic is playing out in AI right now, compressed into a much shorter timeframe. The organizations that recognize it early will have meaningfully more flexibility, lower costs, and better capabilities in three years than those that do not.
What LLM Lock-In Actually Means in Practice
LLM lock-in sounds abstract until you try to change something.
Imagine your organization has spent eight months building a suite of AI agents on a platform that runs exclusively on Azure OpenAI. Your finance agent, your HR query handler, your sales intelligence system - all of them are built on workflows, prompts, and tool configurations optimized for GPT-4o.
Now a new model releases that is significantly better at financial reasoning, costs 40% less per token, and has a longer context window that would let your agents handle larger documents without chunking. You want to switch.
What does that actually involve? You need to re-test every workflow against the new model's behavior, because models do not respond identically to the same prompts. You need to update your platform configuration, assuming the platform even supports the new model. You need to retrain the teams who have learned to work with the existing outputs. You need to re-validate outputs against your compliance requirements. You need to negotiate new terms if the model is from a different vendor.
In a locked platform, that process takes months and significant engineering resources. In an LLM-agnostic platform, it takes an afternoon.
That difference compounds. Over five years, the organization on a flexible platform will have continuously optimized its model selection for cost, performance, and capability. The organization on a locked platform will have done it once, at contract renewal, with significant friction each time.
The Three Types of Lock-In to Watch For
Not all lock-in is obvious. Vendors rarely advertise it as a risk. Here are the three forms it takes and how to identify each one.
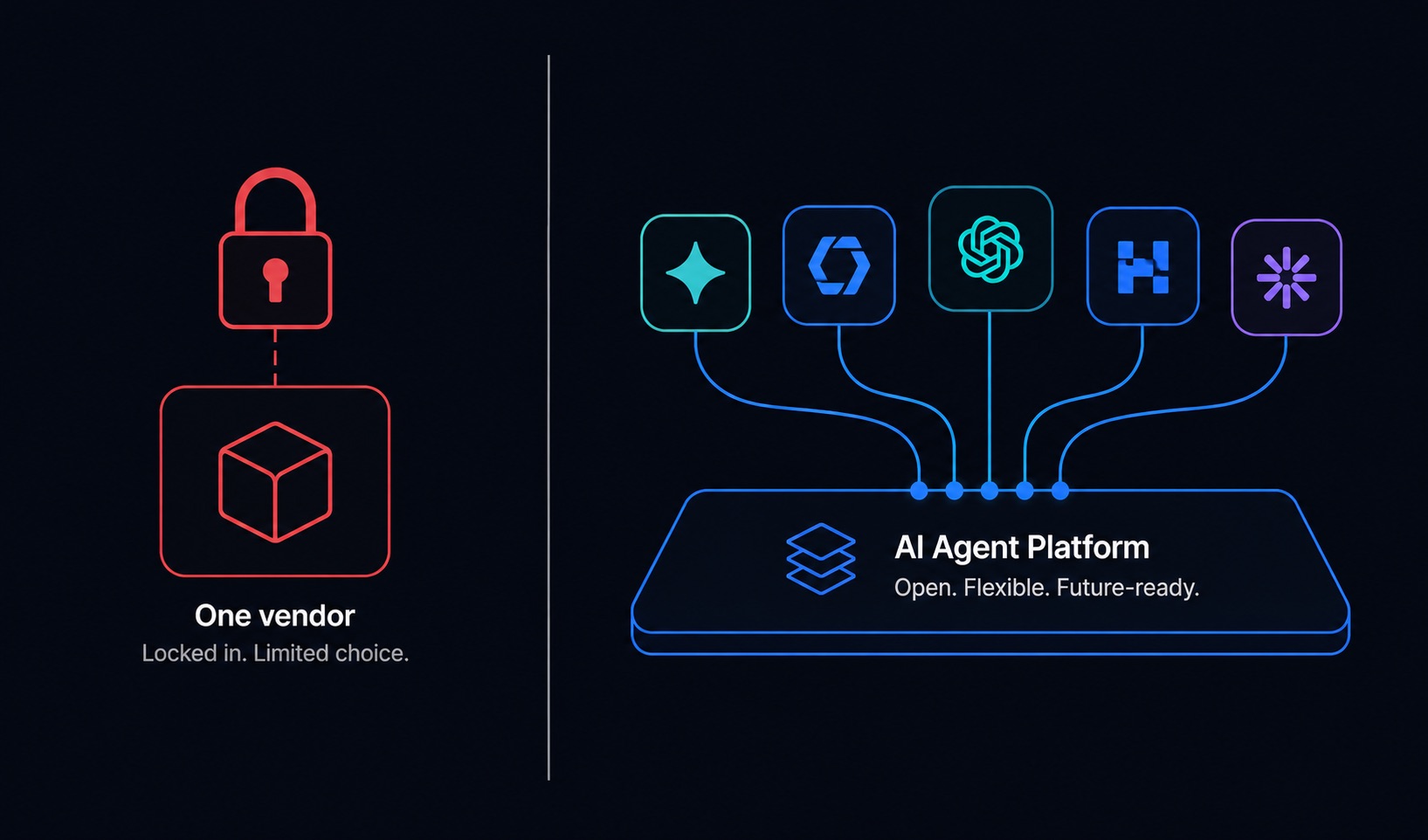
Model lock-in is the most visible form. The platform supports one model provider, or supports others only superficially - a checkbox in the settings that does not actually route production workloads. Ask specifically: can I run the same workflow on GPT-5, Claude Sonnet, and Llama 3 without rebuilding it? Can I switch the model on a live agent without downtime? If the answer is hedged, assume lock-in.
Data lock-in is subtler and often more consequential. When your organizational data - documents, indexed knowledge bases, conversation history, fine-tuning datasets - lives inside a vendor's proprietary infrastructure, leaving becomes exponentially harder. Before signing, ask: where exactly does our data live? Can we export it completely at any time? In what format? What happens to our data if we cancel the contract? The answers to these questions tell you more about the real terms of the relationship than the contract itself.
Deployment lock-in is the third form and the one most likely to become a problem as AI regulation matures. Cloud-only platforms mean your data leaves your infrastructure every time an agent runs. For organizations in regulated industries - finance, healthcare, legal, government - this creates compliance exposure that will only increase as AI-specific regulations develop. Ensure the platform supports private cloud deployment in your own infrastructure, or on-premise deployment for the most sensitive workloads. If those options do not exist today, they will not exist when you need them.
Why Model Diversity Matters Operationally
Beyond avoiding lock-in as a risk, there is a positive case for LLM-agnosticism: different tasks genuinely need different models, and the right architecture lets you match the model to the task.
Consider a typical enterprise workflow - generating a board-level quarterly review. The workflow involves several distinct subtasks: querying structured financial data, retrieving relevant context from internal documents, drafting an executive narrative, and reviewing the draft for factual accuracy against the source data.
These four subtasks do not have the same requirements. The data query step needs a model that is reliable at structured reasoning and SQL generation - not necessarily the most expensive frontier model. The document retrieval step needs strong embedding and retrieval capabilities. The narrative drafting step benefits from the best available language model for long-form writing. The review step needs a model that is particularly strong at factual consistency checking.
A locked platform forces all four steps through the same model, optimizing for none of them specifically. An LLM-agnostic platform lets you route each step to the model best suited for it - and update that routing as better models release, without rebuilding the workflow.
The cost implications alone make this worth taking seriously. Running every task through a frontier model when a smaller, faster, cheaper model would do the job equally well is a significant and entirely avoidable expense at enterprise scale.
What LLM-Agnosticism Looks Like in Practice
Here is a concrete example of how model routing works in a well-designed LLM-agnostic platform.
A financial services firm runs a daily risk monitoring workflow. The workflow has four agents working in sequence:
The first agent queries a PostgreSQL database and a Snowflake data warehouse, running structured SQL to pull current exposure data across trading positions. This step uses a fast, cost-efficient model optimized for structured data reasoning - not a frontier model, because frontier model pricing at this query volume would be prohibitive.
The second agent retrieves relevant context from internal risk policy documents, regulatory guidance, and historical incident reports. This step uses a model with strong retrieval-augmented generation performance and a long context window.
The third agent synthesizes the data and context into a risk narrative for the compliance team. This step uses the firm's preferred frontier model - currently Claude - because the quality of the narrative directly affects compliance officer decisions.
The fourth agent checks the narrative against the source data for factual accuracy before it is sent. This step uses a model specifically strong at consistency verification.
The entire workflow runs on a single platform. The firm can update any individual model selection - say, switching the narrative step from Claude to a new model that outperforms it on financial writing - without touching the other three steps. When a better retrieval model releases, they update that step in an afternoon.
This is what LLM-agnosticism delivers in practice: continuous optimization without continuous rebuilding.
Seven Questions to Ask Any AI Platform Vendor
Before committing to a platform, get specific answers to these questions. Vague or hedged answers are informative.
Can I switch the underlying LLM on a live workflow without rebuilding it? The answer should be yes, with a specific explanation of how model routing is configured.
Can I bring my own API keys for model providers? This matters for cost control, data privacy, and ensuring your usage data does not flow through a third party.
Where does my organizational data live, and can I export it completely at any time? You want a specific answer about data residency - not "in the cloud" - and a clear export mechanism.
Can I deploy this on my own infrastructure? Private cloud and on-premise options should exist for any platform claiming to be enterprise-ready.
What happens to my data if I cancel the contract? You want a clear data deletion policy with a timeline, not a reference to a terms of service document.
Does your platform support models from multiple providers today - not on the roadmap, but in production? Ask for a current list of supported models and whether they are fully supported or in beta.
If a new model releases tomorrow that outperforms your current default, how long does it take for my workflows to have access to it? The answer tells you how responsive the platform's model support actually is in practice.
A vendor that answers all seven questions directly, without deflection, is demonstrating something important about how they think about their customers' long-term interests. A vendor that struggles with any of them is showing you where the lock-in lives.
The Decision You Are Actually Making
When you choose an AI platform, you are not just choosing a tool for today's use cases. You are choosing the infrastructure your organization will build on for the next several years - and the degree of flexibility you will have as the AI landscape continues to change at a pace that makes all prior technology cycles look slow.
The organizations that will have the strongest AI capabilities in 2029 are not necessarily the ones that spend the most or move the fastest today. They are the ones that build on infrastructure flexible enough to absorb the next three generations of model improvements without starting over each time.
LLM-agnosticism is not a technical preference. It is a strategic posture. Choose accordingly.
Ready to see this in action?
Book a 30-minute demo with the RHA One team.